In this post, we will explore:
In simple words, clustering or cluster analysis refers to grouping of observations. It is an unsupervised machine learning technique.
In hierarchical clustering, we group the observations based on distance successively. How the observations are grouped into clusters over distance is represented using a dendrogram. The popular hierarchical technique is agglomerative clustering.

b) Affinity:
Options available in sklearn are : “euclidean”, “l1”, “l2”, “manhattan”, “cosine”, or “precomputed”.


We can also get the cluster centers using this command:

- What is cluster analysis?
- Hierarchical cluster analysis
- K-means cluster analysis
- Applications
In simple words, clustering or cluster analysis refers to grouping of observations. It is an unsupervised machine learning technique.
How we group the observations depends on the type of clustering we choose and measure we choose to calculate the 'closeness'. Even though there are many types of clustering, in this post, let us discuss about two major clustering techniques: hierarchical clustering and K-means clustering.
1. Hierarchical cluster analysis
In hierarchical clustering, we group the observations based on distance successively. How the observations are grouped into clusters over distance is represented using a dendrogram. The popular hierarchical technique is agglomerative clustering.
In agglomerative clustering, at distance=0, all observations are different clusters. That is, each observation is a cluster. As the distance increases, closer observations are grouped into clusters (bottom-up approach). Finally, all the observations are merged into a single cluster.
Divisive clustering (top-down approach) is exact opposite of agglomerative clustering: all observations are grouped into a single cluster, which are then sub-divided into different clusters.
1. A) Advantages of hierarchical clustering
- No need to specify the number of clusters (or K) before the analysis
- Dendrogram gives visual representation of clusters which is informative and provides insights about the observations and clusters
1. B) Disadvantages of hierarchical clustering
- Higher time complexity O(n2 logn) where n=number of observations
- Hence difficult to perform hierarchical clustering on large datasets
- No backtracking: once an observation is grouped into a cluster, it can't be undone
1. C) Example of hierarchical cluster analysis using sklearn
In the following example, let us see how to perform agglomerative clustering in sklearn using Iris dataset.
- Step 1: Standardize
We have to standardize the dataset before performing clustering.
- Step 2: Select hyperparameters: Linkages and affinity measures
In hyperparameters, there are two important concepts: one is the way in which distance between clusters is calculated (linkage) and how distance is measured (affinity).
a) Linkages: {“ward”, “complete”, “average”, “single”}, (default=”ward”)
- Single Linkage: distance between two clusters is the shortest distance between two points in each cluster as shown below.
 |
| Single linkage: shortest distance between clusters |
- Complete linkage (or maximum linkage) considers the maximum distances between observations of the two clusters as shown below.
 |
| Complete linkage: maximum distance between clusters |
- Average linkage considers the average pair-wise distances of each observation of the two clusters.
 |
| Average linkage: average pair-wise distance between clusters |
- Ward's method minimizes the total within-cluster variance.

b) Affinity:
Options available in sklearn are : “euclidean”, “l1”, “l2”, “manhattan”, “cosine”, or “precomputed”.
1. D) Agglomerative clustering using sklearn

However plotting dendrogram is not straightforward in sklearn. You can refer to these links for more on plotting dendrogram (this and this).
2. K-means cluster analysis
2. A) Advantages of K-means clustering
- Computationally faster and hence we can analyse bigger datasets
- Backtracking is possible: observations can be reassigned based on the new centroid
2. B) Disadvantage of K-means clustering
- We need to specify number of clusters (K) before the analysis (apriori knowledge is required)
2. C) Example of K-means cluster analysis using sklearn
The n_clusters refers to number of clusters to be formed and default is 8. Set the random state to get repeatable results.
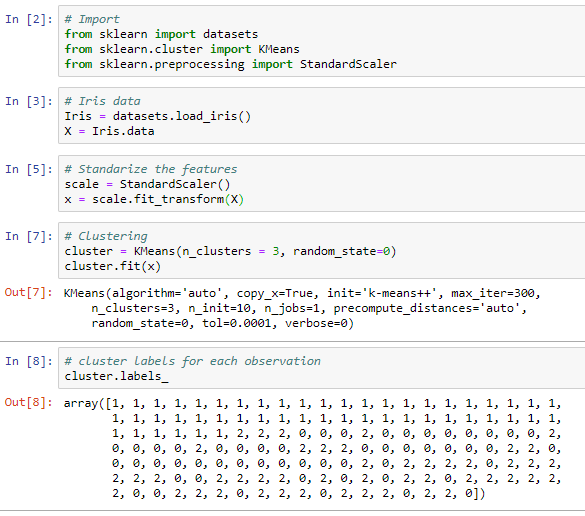
We can also get the cluster centers using this command:

3) Applications of clustering
- Customer segmentation
- Pattern recognition
- Taxonomy research
- Gene studies
- Outlier detection
4) Conclusion
In this post, we have explored the basic concept of clustering. We have also seen hierarchical and K-means clustering examples in sklearn along with advantages and disadvantages.
If you have anything to share, please do share. I will be happy to interact.