In this post, let us understand how to fit a classification model using Naïve Bayes (read about Naïve Bayes in this post) to a natural language processing (NLP) problem.
Extract the files. This dataset contains 5,572 SMS messages, labelled ham (legitimate) or spam.
Step 2: Import the text data set, provide column names.

Step 3: Convert labels (ham and spam) to numbers (0 and 1).

Step 4: Split the dataset into test and train.

Step 5: Vectorize
In this step, words are converted to numerical structure. You can read more on this here.
 Step 6: Vectorize training dataset
Step 6: Vectorize training dataset

Step 7: Vectorize test data set

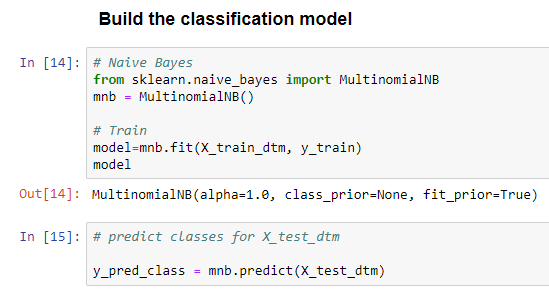
Step 8: Build the Naïve Bayes classification model. If you want to know what is Naive Bayes model, then read my post on Naive Bayes.

Step 9: Measure the accuracy on test data
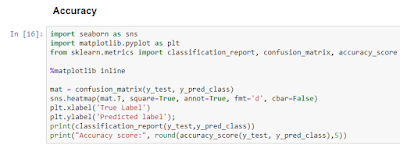

Accuracy of the Naïve Bayes model in classifying the test data is 0.98851.
I have used the codes from the following sites and modified wherever needed:
https://radimrehurek.com/data_science_python/
https://www.ritchieng.com/machine-learning-multinomial-naive-bayes-vectorization/
https://jakevdp.github.io/PythonDataScienceHandbook/05.05-naive-bayes.html
https://scikit-learn.org/stable/tutorial/text_analytics/working_with_text_data.html
Further reference materials:
https://stackabuse.com/python-for-nlp-sentiment-analysis-with-scikit-learn/
https://pythonprogramming.net/naive-bayes-classifier-nltk-tutorial/
https://www.geeksforgeeks.org/applying-multinomial-naive-bayes-to-nlp-problems/
https://towardsdatascience.com/naive-bayes-document-classification-in-python-e33ff50f937e
I personally found this post very helpful: https://www.ritchieng.com/machine-learning-multinomial-naive-bayes-vectorization/
You can find sample datasets on this site https://blog.cambridgespark.com/50-free-machine-learning-datasets-natural-language-processing-d88fb9c5c8da
- Download sample dataset
- Split dataset into test and train data
- Vectorize
- Build and measure the accuracy of the model
Example
Step 1: Let us use publicly available dataset for spam detection. Download the dataset from this site.Extract the files. This dataset contains 5,572 SMS messages, labelled ham (legitimate) or spam.
 |
| Sample dataset: ham or spam? |

Step 3: Convert labels (ham and spam) to numbers (0 and 1).

Step 4: Split the dataset into test and train.

Step 5: Vectorize
In this step, words are converted to numerical structure. You can read more on this here.


Step 7: Vectorize test data set

Step 8: Build the Naïve Bayes classification model. If you want to know what is Naive Bayes model, then read my post on Naive Bayes.
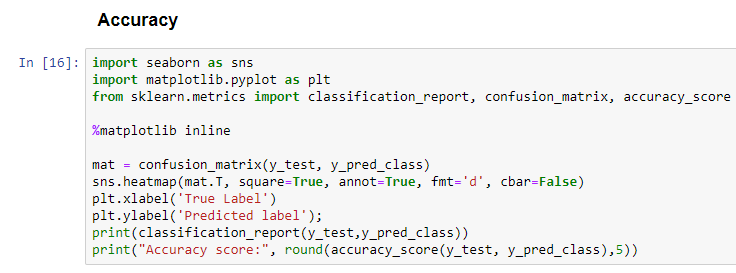
Step 9: Measure the accuracy on test data

References
I have used the codes from the following sites and modified wherever needed:
https://radimrehurek.com/data_science_python/
https://www.ritchieng.com/machine-learning-multinomial-naive-bayes-vectorization/
https://jakevdp.github.io/PythonDataScienceHandbook/05.05-naive-bayes.html
https://scikit-learn.org/stable/tutorial/text_analytics/working_with_text_data.html
Further reference materials:
https://stackabuse.com/python-for-nlp-sentiment-analysis-with-scikit-learn/
https://pythonprogramming.net/naive-bayes-classifier-nltk-tutorial/
https://www.geeksforgeeks.org/applying-multinomial-naive-bayes-to-nlp-problems/
https://towardsdatascience.com/naive-bayes-document-classification-in-python-e33ff50f937e
I personally found this post very helpful: https://www.ritchieng.com/machine-learning-multinomial-naive-bayes-vectorization/
You can find sample datasets on this site https://blog.cambridgespark.com/50-free-machine-learning-datasets-natural-language-processing-d88fb9c5c8da